Are you trying to troubleshoot server down issues?
This guide is for you.
Sometimes, network issues might occur and all the servers in a Datacenter can go down. This can lead us into some unlucky instances.
When servers go down, all of your organization's best-laid plans could very quickly go to waste. From short term costs like productivity and revenue losses to more enduring consequences like compromised data and loss of brand reputation, system downtime has the potential to inflict significant damage to your company.
Here at Ibmi Media, as part of our Server Management Services, we regularly help our Customers to perform Server Optimization tasks.
In this context, we shall look into how we can troubleshoot server down issues.
How to troubleshoot server down issues ?
Initially, we need to make sure if it is a false alert.
To do so, we connect to the server via ping or telnet to any of the running ports and check if it is really down or not.
The commands are really simple:
ping server ip
telnet serverip port numberFor example,
ping 186.65.23.15
telnet 186.65.23.15 22The above commands can perform in different operating systems such as Linux, Mac, or Windows.
If the server responds to the ping fine without any data loss as given below, then everything is fine.
It is a false alert.
-
ping google.com -c10
PING google.com (74.125.129.100) 56(84) bytes of data.
10 packets transmitted, 10 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 326.477/326.477/326.477/0.000 ms
-However, if the server is not responding to ping or has any packet loss, then we recommend contacting DC or hosting providers to get the issue sorted out.
Let us see what one of our customers came across.
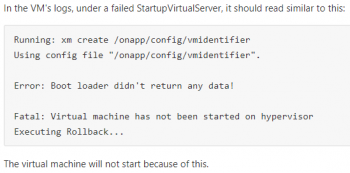
When he received the server down alert, he couldn’t access the server. Even a reboot couldn’t bring the server back online.
So, we connect to the server via IPMI and found that the server was stuck at fsck and that led to the problem.
There can be so many reasons for the server being down.
i. High load in the server
ii. Faulty equipment
iii. High temperature in the DC room
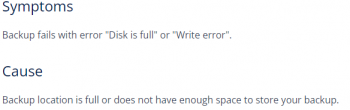
iv. Partition being full
v. No disk space in the server
vi. Power connection cable
If the server is stuck, a reboot from DC is a better option.
Once the server is up, we need to check the reason why it went down.
To find the reason, we refer to the below logs location in the server.
For Linux:
/var/log/messages —
dmesg |grep less
/var/log/boot.log
/var/log/fsckFor Windows:
Start>>Run>>eventvwrSuppose, the load was high due to spam or the number of incoming connections to HTTP being high, we need to troubleshoot accordingly.
However, if the server was down due to a high load, then we check the incoming connections and block them in the server.
If a drive is faulty, then we need to replace them. In our case, the server was running fsck check and that is why it was taking time.
Several reasons may lead to fsck check running:
i. The complete unmounting ability of the hard disk
ii. Using a third-party utility to delete the extended partition
iii. Problems with any filesystems
iv. Power failure
v. Incomplete shut down
vi. Hardware failure
The above causes result in file system operations being incomplete.
The few sample logs we can find in the Linux logs are as below.
Checking all file systems.
[/sbin/fsck.ext3 (1) — /] fsck.ext3 -a /dev/xvda1
/: clean, 56079/1310720 files, 1243508/2621440 blocks
[/sbin/fsck.ext3 (1) — /var/www/virtual] fsck.ext3 -a /dev/sdf
fsck.ext3: No such file or directory while trying to open /dev/sdf
/dev/sdf:The superblock could not be read or does not describe a correct ext2
filesystem. If the device is valid and it really contains an ext2
filesystem (and not swap or ufs or something else), then the superblock
is corrupt, and you might try running e2fsck with an alternate superblock:
e2fsck -b 8193After the fsck check is complete, the server will be up fine without further errors.
[Stuck with server down issues? We can help you through it. ]
Conclusion
This article covers how to troubleshoot server down issues. Basically, network issues might cause the Datacenter to go down. This can lead us into some unlucky instances. Troubleshooting server down issues is never an easy task. Whether you have a small home network, or a super connection of thousands of computers, there are meticulous steps you need to take to get your server back up running.
Steps to take when troubleshooting server down issues:
1. ANALYZE YOUR NETWORK INFRASTRUCTURE
You will have a better chance at troubleshooting network problems if you first figure out where everything is connected in the infrastructure.
2. STUDY YOUR NETWORK
If you don't have an infrastructure design to go by, you will have to learn your network’s layout when analyzing your connectivity. Several tools can help you to map out the entire network infrastructure. Tools such as IPCONFIG can aid in finding the problem.
3. CONNECTION IS DOWN
From the network troubleshooting application, find out from the OSI model if all the seven layers are working correctly. Usually, if the first layer doesn’t work the whole connection will be down. Check whether the network cable is plugged in.
4. NO IP ADDRESS
Your server could be down just because of unknown IP address settings. Anon IP address such as 0.0.0.0 or an automatic one that starts with 169.254 will typically result in server down problems. You will need to obtain a valid IP address before you can get your server back up.
5. NO DNS SERVERS
Without DNS servers configured on your network, all communication will only be possible through an IP address. A server down issue, in this case, might be a broken a line between the router and the internet.
6. NO DEFAULT GATEWAY
Your servers could be down because there is no default gateway IP address. This breaks the communication between the subnet and the local area network. You will still be able to work as usual on your local servers.
7. MISCONFIGURED IP SUBNET MASK
A misconfigured subnet mask IP can impede server communication. You can manually configure this IP subnet mask or work with the DHCP server to identify the source if there is a misconfiguration.
This article covers how to troubleshoot server down issues. Basically, network issues might cause the Datacenter to go down. This can lead us into some unlucky instances. Troubleshooting server down issues is never an easy task. Whether you have a small home network, or a super connection of thousands of computers, there are meticulous steps you need to take to get your server back up running.
Steps to take when troubleshooting server down issues:
1. ANALYZE YOUR NETWORK INFRASTRUCTURE
You will have a better chance at troubleshooting network problems if you first figure out where everything is connected in the infrastructure.
2. STUDY YOUR NETWORK
If you don't have an infrastructure design to go by, you will have to learn your network’s layout when analyzing your connectivity. Several tools can help you to map out the entire network infrastructure. Tools such as IPCONFIG can aid in finding the problem.
3. CONNECTION IS DOWN
From the network troubleshooting application, find out from the OSI model if all the seven layers are working correctly. Usually, if the first layer doesn’t work the whole connection will be down. Check whether the network cable is plugged in.
4. NO IP ADDRESS
Your server could be down just because of unknown IP address settings. Anon IP address such as 0.0.0.0 or an automatic one that starts with 169.254 will typically result in server down problems. You will need to obtain a valid IP address before you can get your server back up.
5. NO DNS SERVERS
Without DNS servers configured on your network, all communication will only be possible through an IP address. A server down issue, in this case, might be a broken a line between the router and the internet.
6. NO DEFAULT GATEWAY
Your servers could be down because there is no default gateway IP address. This breaks the communication between the subnet and the local area network. You will still be able to work as usual on your local servers.
7. MISCONFIGURED IP SUBNET MASK
A misconfigured subnet mask IP can impede server communication. You can manually configure this IP subnet mask or work with the DHCP server to identify the source if there is a misconfiguration.