Are you running out of disk space on the Nagios?
This guide is for you.
Nagios provides enterprise-class Open Source IT monitoring, network monitoring, server and applications monitoring.
Here at Ibmi Media, as part of our Server Management Services, we regularly help our Customers to fix Nagios related errors.
In this context, we shall look into the steps to fix this Nagios disk space problem.
What triggers running out of disk space on the Nagios problem?
Before we get into the solution part of this problem, let’s first see the different causes.
Here are the reasons for this error to occur;
i. Increasing the number of hosts/services has consumed more disk space
ii. Large number of backups
iii. Large log files
Moreover, running out of HDD space on the Nagios XI server can create a large number of problems. The problems include disrupted monitoring, data loss, database corruption, inability to log in to the web interface, and so on.
How we resolve 'running out of disk space on the Nagios' problem?
Now let’s take a look at how our Support Engineers resolve this error.
We always suggest planning ahead and set up the environment in a way that allows for some growth.
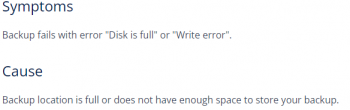
Also, it is better to backup the Nagios XI instance. But if we are saving them locally and do not have a large enough hard drive, we can run out of space very fast.
By default, the backups are stored in /store/backups/nagiosxi/ directory. It is a good practice to keep an eye on this folder and remove the old backups that we do not need.
Also, there are some MySQL and postgres backups in /store/backups/mysql/ and /store/backups/postgresql/ directories. Generally, these are created on daily, monthly, and weekly basis by the /root/scripts/automysqlbackup and /root/scripts/autopostgresqlbackup script.
Both these scripts are run on a cron job. Here is the command we run to view the crontab:
cat /etc/cron.d/nagiosxiThe /store/backups/mysql/ and /store/backups/postgresql/ directories can also grow quite large. If we need to clear some HHD space we could delete some of the old backups that are no longer needed.
We can disable these two cron jobs if we wish. For that, we just comment them out as below;
# 0 7 * * * root /root/scripts/automysqlbackup
# 0 8 * * * root /root/scripts/autopostgresqlbackupIn case, if we’ve poorly configured the checks, system issues, debugging enabled, etc then the log files can grow out of control. So, we temporarily clear some space by deleting old logs that we might not need.
We run the below command to view the 10 largest files under /var/log/ directory;
du -a /var/log | sort -n -r | head -n 10Another option is to add another disk and move the existing data to that location.
Additionally, we can delete some old nagios log files from the /usr/local/nagios/var/archives/ directory, if we don’t need the historical data.
After clearing some space, we will need to resize the virtual machine.
[Need urgent assistance in fixing Nagios disk problems? – We are here to help you]
Conclusion
This article will guide you on how to fix 'running out of disk space on the Nagios' problem.
This article will guide you on how to fix 'running out of disk space on the Nagios' problem.