Are you trying to create robots.txt allow and disallow functionality for your website?
This guide is for you.
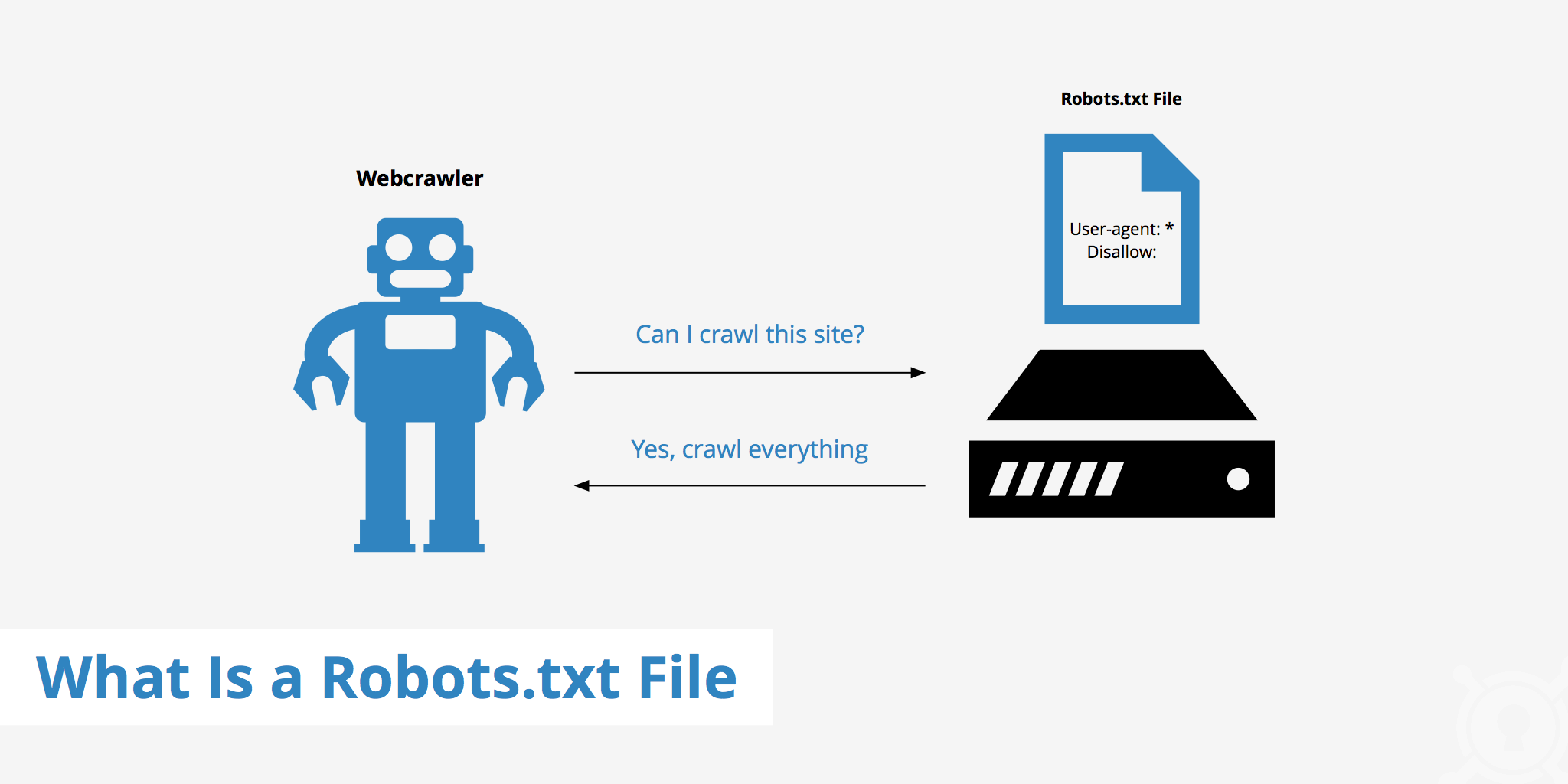
Robots.txt is named by robots exclusion standard.
It is a text file using which we can tell how the search engines must crawl the website.
txt file contains information about how the search engine should crawl, the information found there will instruct further crawler action on this particular site.
If the robots. txt file does not contain any directives that disallow a user-agent's activity (or if the site doesn't have a robots.
Here at Ibmi Media, as part of our Server Management Services, we regularly help our Customers to set up robots.txt for their website and fix related errors.
In this context, we shall explore more on robots.txt.
Robots.txt allow and disallow functionality ?
Robots.txt basically works like a "No Trespassing" sign. It actually, tells robots whether we want them to crawl the website or not.
So, it does not block access.
The robots.txt file belongs to the document root folder.
Now, let's explore more about how to allow and disallow search engine access to website folders using robots.txt directives.
How to Disallow robots and search engines from crawling ?
We can tell search engines which parts or folders it must not access on a website. This is easily done using the 'disallow' directive.
After the directive, we specify a path or the folder name which the search engine must not access. If there is no path or folder mentioned then the directive is ignored.
Here is an example:
User-agent: *
Disallow: /wp-admin/
How to Allow robots and search engines to crawl ?
We can also tell Search engines about which folders it must access while crawling the website. This is easily done using the 'allow' directive.
Using both the allow and disallow directive together we can tell search engines to access only specific directories. And the rest is set to disallow.
Here is an example:
User-agent: *
Allow: /blog/terms-and-condition.pdf
Disallow: /blog/Here, the search engine will not crawl the entire folder blog except the file terms-and-condition.pdf.
Few common mistakes done while creating robots.txt allow or disallow
1. Separate line for each directive while using allow or disallow
When mentioning the directives for allowing or disallowing, each one must be in a separate line.
One of our customers had added the below code in robots.txt and it was not working:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/The above is the incorrect way of mentioning the directives in robots.txt.
We corrected the file by adding it with below code:
User-agent: *
Disallow: /directory-1/
Disallow: /directory-2/
Disallow: /directory-3/Finally, adding this code the robots.txt started working fine.
2. Conflicting directives while using robots.txt
Recently, one of our customers had a robots.txt file with the below code in it:
User-agent: *
Allow: /directory
Disallow: /*.htmlHere, the search engines are unsure about what to do with the URL http://domain.com/directory.html.
Also, it is not clear to them whether they’re allowed to access.
So we modified the code in a better way by adding wildcards:
User-agent: *
Allow: /directory
Disallow: /*.html$In the above code, the search engines don't provide any access to the URLs that end with .html.
However, URLs like https://example.com/page/html?lang=en is accessible as it doesn't end with .html.
[Need urgent assistance with Website robots.txt? – We'll help you. ]
Conclusion
This article will guide you on how to create robots.txt and fix #errors related to it. Basically, we can instruct the crawler as to which page to crawl and which page not to crawl using the #robots .txt allow and disallow directives.
Web site owners use the /robots. txt file to give instructions about their site to web robots; this is called The Robots Exclusion Protocol.
The "Disallow: /" tells the robot that it should not visit any pages on the site.
1. The robots. txt file can tell crawlers where to find the XML #sitemap file(s), how fast the site can be crawled, and (most famously) which webpages and directories not to crawl.
2. The robots. txt file, also known as the robots exclusion protocol or standard, is a text file that tells web robots (most often search engines) which pages on your site to crawl.
3. It also tells web robots which pages not to crawl.
txt file.
4. The asterisk after “user-agent” means that the robots.
This article will guide you on how to create robots.txt and fix #errors related to it. Basically, we can instruct the crawler as to which page to crawl and which page not to crawl using the #robots .txt allow and disallow directives.
Web site owners use the /robots. txt file to give instructions about their site to web robots; this is called The Robots Exclusion Protocol.
The "Disallow: /" tells the robot that it should not visit any pages on the site.
1. The robots. txt file can tell crawlers where to find the XML #sitemap file(s), how fast the site can be crawled, and (most famously) which webpages and directories not to crawl.
2. The robots. txt file, also known as the robots exclusion protocol or standard, is a text file that tells web robots (most often search engines) which pages on your site to crawl.
3. It also tells web robots which pages not to crawl.
txt file.
4. The asterisk after “user-agent” means that the robots.